










ニュース
NVIDIA,製品ロードマップを更新。次次世代GPUアーキテクチャ「Volta」と次次世代Tegra「Parker」の概要が明らかに
 |
本稿では,本格的にセッションが始まる現地時間19日の朝に行われた,NVIDIAの総帥・Jen-Hsun Huang(ジェンスン・フアン)氏による基調講演のなかから,最も注目されるロードマップ周りをお伝えしてみたい。主力GPUアーキテクチャでは「Volta」,モバイルSoC(System-on-a-Chip)では「Parker」という,初公開の開発コードネームが登場し,さらに,開発コードネームが公表されていた「Maxwell」「Logan」の概要も明らかになるなど,注目点は多い。
Maxwellは単一の仮想メモリに対応
Voltaではメモリ帯域幅の課題に挑戦する
まずは主力GPUアーキテクチャのロードマップから見ていこう。
 |
まずは,2014年の市場投入が予定されている次世代GPUアーキテクチャ,Maxwell(マクスウェル)だが,Huang氏は,この世代で「Unified Virtual Memory(統合型仮想メモリ)をサポートする」と明言した。Huang氏の言葉をそのまま借りるなら,「GPU側からCPU側の仮想メモリ空間を参照でき,逆にCPU側からもGPU側の仮想メモリを参照できる」ため,GPUプログラミングが極めて容易になるという。
CUDAを追いかけている人なら,ここで疑問符が浮かんだかもしれない。少なくともCUDAフレームワーク上では,CUDA 4の世代から,GPUとCPUのメモリ空間を単一のものとして扱える「Virtual Memory Addressing」(仮想メモリアドレッシング)がサポートされているからだ。
ただし,いま述べたとおり,現在のVirtual Memory AddressingはあくまでもCUDAのフレームワーク上で論理的に実現されるものであり,GPUのメモリとCPUのメモリは,物理的に分かれている。そのため,必要に応じてGPUとCPUとの間でメモリコピーなどが行われることになる。
 |
たとえば基調講演のなかでHuang氏が述べたように,「GPUとCPUが自由に相互の仮想メモリを参照する」ためには,GPUとCPUとがアドレス変換テーブルを相互に参照できなければならない。アドオンカードという形を取る場合はそこがハードルで,現状ではソフトウェアフレームワークを使って実現せざるを得ない部分である。Huang氏は,「MaxwellでどのアーキテクチャのCPUと仮想メモリ空間を共有するのか」を語っていないので,いまのところ,これ以上は推測しようがないが。
なお,詳細は後述するが,将来のTegraではMaxwellベースのGPUが統合される予定になっている。Maxwell世代のGPUコアが統合されたTegraなら,文字どおりのUnified Virtual Memoryを容易に実現できるはずだ。
ここからは想像だが,Maxwell世代のGPUコアが統合された将来のTegraでは,Unified Virtual Memoryをハードウェア的に実現する一方,PC上のGPUでは部分的にソフトウェアやARMコアの支援を使って実現することで,両者の互換性を維持させていくという形を取る可能性はある。
いずれにせよ,NVIDIAは将来的に,ARMベースの独自CPU投入計画を持っている。MaxwellにおけるUnified Virtual Memoryは,それに向けた一里塚ということになりそうだ。
……というわけで,Maxwellの後継として,今回初めてその名が明らかとなったVolta(ヴォルタ)である。NVIDIAはCUDAに対応した主力GPUアーキテクチャの開発コードネームに物理学者の名前を与え続けているので,18世紀イタリアの物理学者・Alessandro Volta(アレッサンドロ・ヴォルタ)からその名が取られたという認識で間違いないだろう。
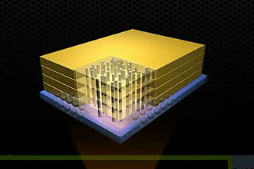 |
Stacked DRAM(スタック型DRAM,Stacked Memoryともいう)というのは,文字どおり,DRAMチップを積み重ねたものだ。「VoltaではGPUと同じシリコン基板上にDRAMが実装され,積み重ねられたDRAMの“層”は,シリコンを貫く穴によって接続される」と,Huang氏は説明している。
現在,スマートフォン向けのSoCでは,SoC上にDRAMチップを積層している製品がある――これはメモリバス帯域幅のためではなく,実装面積を小さくするため――が,それの大規模版といった技術と考えていいだろう。
 |
気になるメモリバス帯域幅は,1TB/sという,驚異的なものになるという。Huang氏は「Blu-ray Disc 1枚分のデータをわずか50分の1秒で読み出せる」と述べていたが,「GeForce GTX TITAN」が288.38GB/sなので,その4倍弱であり,実現すれば確かに,グラフィックスにも大きなインパクトをもたらしそうだ。
Voltaに関して一点気になるのは,ロードマップの横軸に投入時期の記載がなかった点である。Stacked DRAMの実現には製造上の技術進歩が求められるだけに,NVIDIAだけでは時期が読み切れないという部分があるのかもしれない。
NVIDIA製CPUコアが統合される次次世代Tegra「Parker」は2015年の登場予定
NVIDIAにとってもう1つの重要な軸となるTegraのロードマップも,下のとおり示されている。
Huang氏はTegraシリーズの歴史を振り返りつつ,2014年の登場予定となっているLogan(ローガン)が,「Kepler世代のGPUが統合され,CUDAをサポ―トする最初のモバイルプロセッサになる」と明言。会場から拍手を受けていた。
 |
Loganでは,CUDA 5の完全対応を果たすほか,次世代のグラフィックスAPIであるOpenGL 4.3や,NVIDIAの物理シミュレーション技術であるPhysXのハードウェアアクセラレーションにも対応するとのこと。TegraにおけるCUDAサポートは開発者の間で待ち望まれており,Tegra 4での非対応が明らかになると落胆が広がったものだが,Loganでついに対応が実現するわけだ。
そのLoganに関連してHuang氏が「Loganのガールフレンド」として披露したのが,「Kayla」(カイラ)だ。Tegraの開発コードネームはMarvel Comics(マーヴェル・コミックス)に登場するアメコミのキャラクターから取られているので,初期作品でLoganの恋人として登場したKayla Silverfoxがその由来ということでいいだろう。
 |
 |
 |
ちなみに「Kaylaはタブレット端末のサイズだが,Loganは10セント硬貨のサイズになる」とHuang氏。つまり,Kaylaで見られるGPU性能は,2014年には10セント硬貨大のSoCで実現されると氏は予告しているわけだ。
そして,その次に来るTegraがParker(パーカー)となる。Spider-Man(スパイダーマン)の主人公・Peter Parker(ピーター・パーカー)からその名が取られたと思われるこの次次世代Tegraは,「Project Denver」,つまり,ARMアーキテクチャに基づいてNVIDIAが独自に開発している64bit対応のCPUコアと,Maxwell世代のGPUコアとが統合されるという。Intelがいうところの3次元トライゲート・トランジスタ技術である「FinFET」を用いて製造されることも,Huang氏の口からは明かされている。
興味深いのは,ロードマップの横軸で,Parkerが2015年とされていることだ。Parkerの製造を請け負うと見られるTSMCのFinFETは2013年中にテストチップが製造されるという状況なので,2015年というのは割と余裕のないスケジュールではないかと思う。
ともあれ,2011年のTegra 2から数えて5年でParkerを実現することに関してHuang氏は「5年というのはムーアの法則で性能が8倍になると予測される期間だが,我々は同じ5年でTegraの性能を100倍に引き上げる」という表現を用いていたことは指摘しておきたい。
以上,約2時間半にも及んだHuang氏の基調講演のうち,ごくわずかな部分を占めたロードマップに踏み込んでお伝えしてみた。NVIDIAのロードマップは定期的にアップデートされ,とくに市場投入時期はズレることが多々あるが,アーキテクチャの進む方向性は見えたと述べていいだろう。あとは順調に進むのを期待したいところだ。
- 関連タイトル:
 GeForce GTX 900
GeForce GTX 900 - 関連タイトル:Volta(開発コードネーム)
- 関連タイトル:Tegra
- 関連タイトル:Project Denver(開発コードネーム)
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー