















ARMのミドルレンジCPUコア「Cortex-A12」の詳細が明らかに。Cortex-A9の弱点だった浮動小数点演算性能の改善を目指す
 |
その中では,同社の製品ロードマップや最新技術について,たくさんの講演やセッションが行われたのだが,そうしたセッションの1つで,2013年6月のCOMPUTEX TAIPEI 2013で発表された新CPUコア「Cortex-A12」の詳細が公開された。
ここではセッションの内容を元に,Cortex-A12の特徴を説明してみたい。なお,Cortex-A12に関しては,こちらの記事も参照してほしい。
[COMPUTEX]ARM,新CPUコア「Cortex-A12」とGPUコア「Mali-T622」などを発表。200~350ドル台の低価格スマートフォンを狙う
Cortex-A9を置き換えるミドルレンジ向けCPUコア
 |
SoC(System-on-a-Chip)ベンダーはこれらを組み合わせて,独自のSoCを製造する。たとえば,NVIDIAのSoC「Tegra 4」では,Cortex-A15を5基集積して,そのうち4基をメインCPU,1基を低消費電力動作専用のコンパニオンコアとして使うという具合だ。
余談になるが,スマートフォンでお馴染みのQualcomm製「Snapdragon」シリーズは,Qualcommが独自に開発したCPUコア「Krait」シリーズを集積しているので,Cortex-Aシリーズは使っていない。
Cortex-A9は,Cortex-A15とCortex-A7の中間に位置するとはいうものの,発表されたのが6年も前の2007年という,年季の入ったCPUコアである。ミドルレンジCPUとしては,性能や機能面で不満が出てくるのも無理はない。そこで,
Cortex-A9の弱点だった浮動小数点演算を強化
それではCortex-A12とは,どのような特徴を持ったCPUコアなのだろうか。内部構造から見ていこう。
Cortex-A12は,最大4CPUコアのマルチコア構成が可能なCPUコアで,各コアごとにSIMD演算ユニット「NEON data engine」と浮動小数点演算ユニット(Floating Point Unit),命令用とデータ用それぞれのL1キャッシュを備えている。
 |
 |
そのほかに細かい部分を見ていくと,CPUコア外にあるメモリコントローラとは,128bitのシステムバスで接続されており,I/O用には別のシステムバスも備える。また,GPUとのキャッシュ一貫性(キャッシュのコヒーレンシ)を保つための機構も備わっているという。このあたりの基本的な構成は,今までのCortex-Aシリーズと比べても,大きな違いはない。
以下に掲載した図は,筆者が作成したCortex-A12の詳細なブロック図だ。上から順に,命令が流れるとイメージしてほしい。一番上にある赤い部分が,メモリから命令を読み出す部分(フェッチ,Instruction Fetch)で,命令用のL1キャッシュや,命令の分岐予測するための分岐予測器(Branch Prediction)もここに置かれている。
IntelやAMDのCPUと同様に,Cortex-AシリーズのCPUコアはARMv7命令を内部処理用の「マイクロ命令」(以下,μOPS)に変換して実行する。その変換を担当するのが,次の命令デコーダ(Decorder)だ。ARMv7命令はここで,1~複数個のμOPSに変換されたうえで,整数系の命令と各種浮動小数点演算命令に分けられる。図の左側が整数系,右側が浮動小数点演算命令を処理するユニットだ。Cortex-A12の性能向上で重要なのは,この右側である。
 |
なぜ,浮動小数点演算命令の処理が重要なのか? それはCortex-A9が,この処理性能が低いと評されていたからだ。そもそもCortex-A9では,浮動小数点演算機能はオプション扱いの機能だった。そのため,これを搭載しないSoCも珍しくはない。分かりやすい例でいうと,NVIDIAの「Tegra 2」は,通常の浮動小数点演算機能のみを備え,ベクトル演算用のNEONは未実装だった。
また,浮動小数点演算機能を搭載していても制約があった。Cortex-A9のCPUパイプラインは,ロードストア用の命令経路を利用して浮動小数点演算ユニットに命令を送っていた。そのため,ロードストア処理のユニットと浮動小数点演算のユニットを切り替えて使う必要があったわけだ。しかし,この構成では,ロードストアで処理が続くと,浮動小数点演算ユニットに命令を発効できなくなる。結果としてCortex-A9は,浮動小数点演算時に性能が低下していたわけだ。
そこでCortex-A12では,浮動小数点演算機能を必須としたうえで,完全に独立したパイプラインとすることで性能向上を狙った。
詳細ブロック図右下にある,先頭に「F」と書かれたユニットが浮動小数点演算用で,同じく「I」は整数演算用,「V」はベクトル演算命令用のユニットになる。たとえば,「FDIV」は浮動小数点の割り算を行うユニットで,「IALU」は整数の加減算や論理演算などを行うユニットだ。
浮動小数点演算ユニットが処理するSIMD命令のNEONは,128bitのデータに複数のデータ――整数なら8~64bit単位のデータを――に詰め込んで,1命令でこれらを同時に計算することで,データ1つ1つに同じ処理を繰り返すのに比べれて高速な計算を可能とするものだ。覚えている人もいるだろうが,Intel CPUにおける「SSE」と同じ理屈である。
次に掲載した図は,Cortex-A12のパイプラインステージを図にしたもので,クロックごとに動作する各ステージとそのつながりをおおまかに説明したものと考えればいい。Cortex-A12では,このパイプラインの段数が,Cortex-A9の9段から,11段へと増やされている。一般的にいえば,パイプライン段数が多くなると,動作クロックを上げやすくなるので,ここでも性能強化が可能となるわけだ。
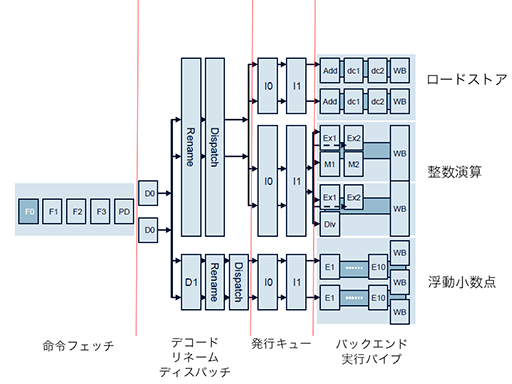 |
このパイプラインは左から右に向かって,命令が流れていく。「F0」から「PD」までは,命令をキャッシュから読み出す処理をこなす。
次の「D0」は命令デコーダで,整数命令はここでデコードが完了するが,浮動小数点演算命令は,さらに「D1」というデコードステージも通る必要がある。浮動小数点演算命令は本来コプロセッサ用の命令であり,一部に整数側の処理が必要になるからだ。これらの役割分担の詳細は不明であるものの,D0でまずコプロセッサ命令にデコードしたうえで,D1でコプロセッサ命令の内部をさらに分解して,処理を決定するといった動作になっているのだと思われる。
Cortex-A9に対して20~50%程度の性能向上を実現
ここまで見てきたように,Cortex-A12は,浮動小数点演算処理の改良やパイプラインの増加などによって,性能向上を目指したCPUコアとなった。ARMではCortex-A9と比べて,40%程度の性能向上を実現したと謳っている。下に掲載したスライドは,いくつかのベンチマークテスト結果のグラフを示したもので,
 |
性能が向上したといっても,より高速なCortex A-15やハイエンドには64bit対応の「Cortex-A50」シリーズがあり,性能を重視したハイエンドのスマートフォンやタブレットには,そちらが採用されるはずだ。Cortex-A12が狙うのはあくまでもCortex-A9の後継であり,日本で販売される製品でいうなら,ショップブランドや輸入品の低価格タブレットに採用されるSoCがターゲットとなるだろう。
つまり,Cortex-A12が普及していけば,低価格タブレットの性能向上が期待できるわけで,今では「安かろう遅かろう」なこれらの実用性も,今後は改善されていくと思われる。来年には低価格タブレットでも,軽快な動作が期待できるようになる……かもしれない。
Cortex-A12の製品情報ページ(英語)
- 関連タイトル:
 Cortex-A
Cortex-A
- この記事のURL:
�尊�贈�造�孫�造�属�造��|�造�足�造�束 G123�造�貼�促�族�臓�村�促��
����続�其�臓�臓�則G123
4Gamer.net最新情報
プラットフォーム別新着記事




総合新着記事




企画記事




新着連載
新着レビュー