













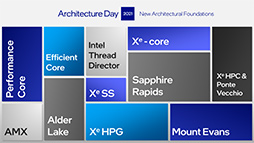
Intelの次世代CPU「Alder Lake」は,高性能コアと高効率コアを組み合わせてPC向けCPUに変革をもたらす
 |
とくにAlder Lakeは,市場投入が近いこともあり,やや踏み込んだ内容が明らかになっている。本稿では,新たに明らかになった内容を含めてAlder Lakeに関する概要をまとめてみたい。
Intelが培ってきた半導体技術を統合するAlder Lake
Alder Lakeの話を始める前に,Intelのクライアント向けCPUについて,簡単におさらいしておこう。
 |
Rocket Lakeに採用されているCPUコアアーキテクチャ「Cypress Cove」は,10nmプロセスを採用するノートPC向け第10世代Coreプロセッサ「Ice Lake」(開発コードネーム)のCPUコアアーキテクチャ「Sunny Cove」を,14nmプロセス技術にバックポート(後方移植)したものだ。
 |
Gemini LakeやJasper Lakeは,かつて「Atom」と呼ばれていた低消費電力プロセッサに端を発するCPUであり,Sunny Coveとは大きく異なるものだ。処理性能はそれほど高くないが,低い消費電力で動作することを重視した設計となっているのが特徴だ。ただ,Windowsタブレットやエントリー市場向けノートPC向けの「Celeron」ブランドや「Pentium Silver」ブランドで使われたプロセッサであり,ゲーマー向けPCに採用されることはないので,4Gamer読者にはあまり馴染みがないかもしれない。
以上をざっくりとまとめるなら,Intelには今,処理性能を重視するデスクトップPCやノートPCが用いる「Cove」系と,省電力性能を重視した「mont」系という,2系統のCPUコアアーキテクチャがあるわけだ。
さて,ここからが本題だが,Alder Lakeは,これら2種類のCPUコアを1つのプロセッサに混在させたうえで,Intel独自のGPUアーキテクチャ「Intel Xe」ベースのGPUや,AIアクセラレータといった技術を統合して実装するという。
Intelは,こうした混成アーキテクチャを「Hybrid Computing Architecture」と称している。
 |
Alder Lake最大の特徴は,Cove系のCPUコアと,mont系のCPUコアの両方を搭載する点だ。高負荷の処理はCove系CPUコアに,優先度の低いバックグラウンド処理をmont系のCPUコアに任せるという,Arm系でいうところの「big.LITTLE」アーキテクチャ的な仕組みを取り入れたとも言えよう。
Armがbig.LITTLEアーキテクチャを発表したのは2011年のことで,現在のスマートフォン向けSoCでは定番の仕組みだから,それ自体に目新しさはない。しかし,異種のCPUコアを組み合わせる設計は,クライアントPC向けのx86プロセッサとしては初となる。なので,PCにとって大胆かつ大きな変化をもたらす変化と言っていい。
Intelは,処理性能重視のCPUコアを,「Performance」の頭文字から「P-Core」と,電力効率重視(高効率)のCPUコアは,効率を意味する「Efficient」の頭文字をとって「E-Core」と呼んでいる。Alder LakeのP-Coreには,Tiger LakeがCPUコアに採用している「Willow Cove」の後継となる「Golden Cove」を,E-Coreにはmont系CPUコアの最新版「Gracemont」アーキテクチャを採用しているとのことだ。
 |
Skylake以上の性能を持つGracemont
E-Core,P-Coreの概要をざっくりと見ていこう。
Atom系というと,かつてのAtomプロセッサの性能から「どうにもならないほど遅い」というイメージを持つPCユーザーも少なくないようだ。しかし,Gemini Lake(Goldmont)以降は,かなりの性能向上を果たしており,数年前のCore i3クラスと遜色ない程度の性能が得られるようになっている。
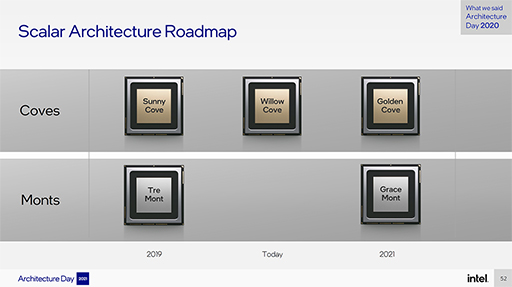
Gracemontは,前世代のTremontをさらに拡張して,電力効率重視といえども高い性能が期待できるアーキテクチャになっている。Gracemontにおける拡張のポイントを纏めたのが,次のスライドだ。
 |
Gracemontでは,フロントエンド,バックエンドともに拡張されている。まず命令を取り込み実行ステージに送るフロントエンドでは,L1命令キャッシュの容量がTremontの32KBから64KBへと倍増している。
x86命令を「μOP」(マイクロオプス)と呼ばれる実行単位の命令に分解する命令デコーダは,1クロックあたり3命令×2の合計6命令/クロックという仕様だ。ここはTremontと変わらずだが,Intelとしては初めて,命令長デコード履歴を命令キャッシュに保存して,命令デコードの効率を上げるオンデマンド型命令長デコーダを備えているという。
そのほかに,分岐予測(Branch Prediction)バッファがTremontの1000エントリから,5000エントリへと大幅に拡張されたのもポイントだ。
 |
フロントエンドでμOPに分解された命令は,Out-of-Order(アウトオブオーダー,順不同)で命令実行ポートに送られるが,ここも強化されたことで,GracemontはTremontよりも同時に処理できる命令数が増えたと理解していい。
 |
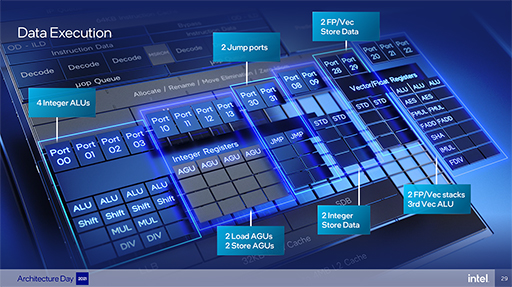
命令実行ポートも17ポートに増えた。Tremontは10ポートだったので,1.7倍もの命令を実行できるようになっている。参考までに,「Gracemont(Tremont)」という書式で,命令実行ポートのスペックを示しておこう。
- 整数ALU:4(3)
- ロード/ストアアドレス生成ユニット(AGU):それぞれ2基ずつの4(2)
- 分岐ポート:2(1)
- 整数データストアユニット:2(1)
そのほかに,浮動小数点演算命令(FP)やAVX命令(ベクトル,Vec)の実行ユニットも強化され,新しくFP/ベクトルストアが追加となった。
- FP/ベクトルALU:3(2)
- FP/ベクトルストア:2(0)
 |
なお,P-CoreとE-Coreを負荷に応じて動的に切り替えるAlder Lakeでは,P-CoreとE-Coreがまったく同じ命令セットをサポートしている必要がある。そのためIntelによると,E-CoreのGracemontでは,AVX命令はもちろん,セキュリティ上のリスクを防止する「Intel
 |
Gracemontでは,命令実行を支える足回りも拡張されている。L1データキャッシュ容量は,Tremontと同じ32KBだが,複数のE-Coreで共有するL2キャッシュ容量はデータ2MB,命令2MBの合計4MBを備えるという。
 |
ざっくりとした印象で言うと,GracemontはTremontに対して,1.5倍前後の規模感といったところだろうか。Tremont世代で相応の性能向上を実現していたので,Gracemontの性能は低消費電力コアとは言えど,なかなか高いのではなかろうか。
Intelによると,シングルスレッド処理におけるE-Coreの性能は,2016年に登場したデスクトップ/ノートPC向けSkylake世代と比較すると,40%以下の消費電力で同等以上の性能を発揮するという。また,Skylake世代と同じ消費電力であれば,Gracemontは40%も高い性能を発揮するそうである。
 |
一方,マルチスレッド性能であるが,2コア4スレッドのSkylake世代に対して4コア4スレッドのGracemontは80%高い性能を持つという。そして同じ性能なら,消費電力はSkylake世代の20%,つまり8割も低いというから驚きだ。
なお,mont系コアはマルチスレッド技術「Hyper Threading Technology」に対応していない。次世代のGracemontも同様で,そのためSkylakeの2コア4スレッドとGracemontの4コア4スレッドで比較しているわけだ。
 |
前世代に対して19%の性能向上を果たしたP-Core
続いては,Alder Lakeの高性能コアとなるP-Coreを見ていこう。
先述したように,P-Coreは,Willow Coveの後継となるGolden Coveを採用している。Intelによると,Golden Coveにおける改良のコンセプトは,「広く,深く,スマートに」なのだそうだ。広くと深くは,E-Coreと同じ考え方と理解していいだろう。
 |
P-CoreのフロントエンドにおけるWillow Coveからの変更点を,スライドで見ていこう。
 |
目立つところを見ていくと,命令デコーダが,従来の16byteフェッチから32byteフェッチへと広くなり,さらに命令デコーダ自体も4基から6基に増えている。それに加えて,L1命令キャッシュの容量はWillow Coveと同じ32KBだが,L1 TLB(Translation Lookaside Buffer)が,128エントリから256エントリへと拡大された。
デコーダの拡張は,分岐予測のペナルティが大きくなる可能性があるが,これに対しては分岐予測の精度向上で対応しているようだ。
アウトオブオーダー実行を支えるミッドステージは,アロケーション数が5から6に拡大された。つまり,従来のWillow Coveが5命令/クロックが基本だったのに対して,Golden Coveでは6命令/クロックが基本になるわけだ。
リオーダーバッファも352エントリから512エントリへと拡大されており,アウトオブオーダーウインドウは約1.5倍になった。さらに,命令実行ポートもWillow Coveの10ポートから,12ポートに増強しているという。
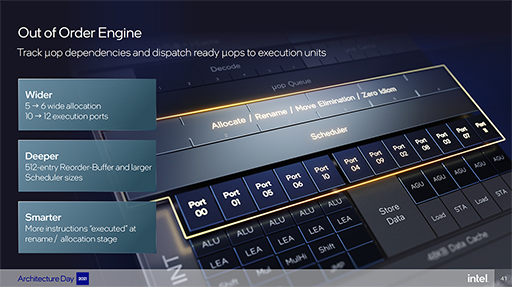 |
命令実行ステージでは,整数ALUとLEA(実行アドレス計算)を備える5番めの実行ポートが追加された。また,浮動小数点演算ユニットでは,低遅延のFADD(加算)ユニットが追加されているという。
さらに積和演算では,AI処理で用いることの多い16bit浮動小数点演算(FP16)をサポート。AVX命令でFP16を高速に処理することができるようになるそうだ。
 |
 |
足回りにも目を向けると,アドレス生成ユニットを備えたロードユニットが増設され従来のロード2ポートからロード3ポートに拡張されたほか,AVX命令ではL1キャッシュから256bit×3または512bit×2のロードが可能になった。
また,L1データTLBは64エントリから96エントリへと拡張されているという。
 |
L2キャッシュはCPUコアごとに1.25MBを実装している。なお,サーバー向けプロセッサのP-Coreでは,L2キャッシュ容量が2MBになるそうだ。
 |
これらの改良により,Intelのラボが同一クロックでGolden CoveとWillow Coveを比較したところ,平均19%の性能向上を果たしたとのこと。
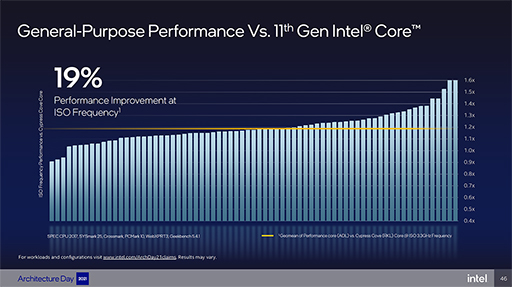 |
なお,ゲーマーにはあまり縁のない話になるが,サーバー向けプロセッサで用いるGolden Coveは,AI処理向けのマトリックス演算に対応する「Intel Advanced Matrix Extensions」(Intel AME)という命令セットに対応するそうだ。
Intel AMEは2次元的に配列したレジスタを持ち,2048個の8bit整数演算や,1024個のbfloat16(※AI処理で用いる16bit浮動少数点数)演算などが行えるという。
 |
Alder Lakeの性能を最大に生かせるのはWindows 11以降
以上のように,Alder LakeのE-Coreは,Skylake世代のCPUコアを上回る性能を発揮し,一方のP-Coreは,Tiger Lake世代のCPUコアから平均19%の性能向上を果たしたとまとめられる。
繰り返しになるが,P-Coreは,処理負荷が高いスレッド(プロセス)の処理に割り当てられ,E-Coreは,バックグラウンドタスクのように処理負荷があまり高くないスレッドが割り当てられる。この割り当ては,基本的に自動で行われるものの,OSのスケジューラが対応することで,より高い性能が得られるという。
同じような話は,Armが2011年にbig.LITTLEアーキテクチャを発表した頃にもあった。当時,高性能側のbigコアと高効率(低消費電力)側のLITTLEコアは自動的に切り替わるという話だった。しかし,蓋を開けてみるとなかなかうまく行かず,OSの内部でスレッドの実行とCPUへの割り当てを担うスケジューラの介在が必要になったのだ。
そこでArmアーキテクチャでは,Arm向けLinux環境の開発を主導する組織「Linaro」が中心になって,big.LITTLEアーキテクチャ向けのLinuxカーネル用スケジューラを開発した過去がある。
余談だが,big.LITTLEアーキテクチャにおけるOSスケジューラの仕組みをざっくり説明すると,存在するスレッドを分析して,CPU時間を消費しているスレッドを性能の高いbigコアに優先的に割り当てるという,少々複雑なことやっている。
P-CoreとE-Coreを備えるAlder Lakeでも,big.LITTLEアーキテクチャと同じ問題が生じるだろう,そこでIntelは,OS側スケジューラにおけるCPUコアの割り当てを支援する「Intel Thread Director」(インテルスレッドディレクタ,以下 Thread Director)というハードウェアをAlder Lakeに実装した。これが先行するbig.LITTLEアーキテクチャにはない点だ。
Intelによると,Thread Directorは,ナノ秒(ns)精度でスレッドが実行中の命令を解析して負荷を分析したうえで,その情報をOSのスケジューラにフィードバックするハードウェアであるそうだ。Thread Directorから得られる情報をもとにして,OSがP-CoreとE-Coreを適切に使い分けることで,Alder Lakeの性能は,最大限に発揮できるという。
 |
ただし,Alder Lakeに最適化したスケジューラがOSに組み込まれるのは,Windows 11からとのこと。もちろん,Windows 10でもP-CoreとE-Coreは自動で使い分けられるので,利用できないわけではない。しかし,Windows 11に比べると使い分けの効率が落ちる可能性は高いだろう。ここは注意しておきたいポイントだ。
超薄型モバイルから高性能デスクトップまでをカバーするAlder Lake
Intelの現行製品はノートPC向けで10nmプロセス技術で製造されるTigre Lakeと,デスクトップPC向けに14nmプロセス技術で製造されるRocket Lakeという2つの系統に分かれている。
ほんの数年前までIntelは,デスクトップPCとノートPCで同じマイクロアーキテクチャを用いたCPUを提供していた。しかし,14nmプロセス以降のプロセス開発に難航したうえ,高性能と低消費電力の両立が困難になり,今ではデスクトップPCがRocket Lakeに,ノートPCがTiger Lakeにと,2系統に分かれてしまっている。
しかしAlder Lake世代では,薄型ノートPCから高性能なデスクトップPCまで,幅広い市場に向けた製品を同じマイクロアーキテクチャでカバーする環境が復活する。TDPで言うなら,9Wクラスの薄型ノートPC向けから,125Wに達する高性能デスクトップPCまでを,Alder Lakeでカバーする計画であるそうだ。
 |
 |
幅広いTDPをカバーできるのは,P-CoreとE-Coreの構成を変えられるからだ。現時点でIntelが明らかにしている構成は,次の3種類となる。
- 高性能デスクトップPC向け:P-Core×8,E-Core×8
- 高性能ノートPC向け:P-Core×6,E-Core×8
- 薄型ノートPC向け:P-Core×2,E-Core×8
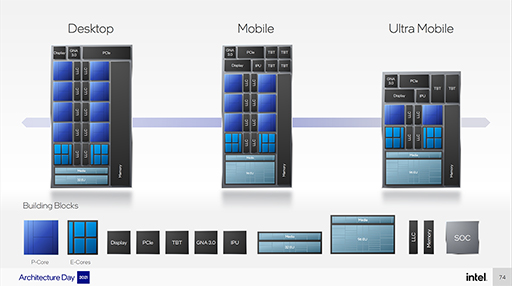 |
最も高性能なデスクトップPC向けAlder Lakeは,「LGA 1700」と呼ばれる新しいCPUパッケージとソケットで提供される。P-CoreとE-Coreを合わせると16基のCPUコアを持ち,P-Coreで16スレッド,E-Coreで8スレッドの計24スレッドを同時実行できる仕様だ。なお,L3キャッシュ容量は30MBに達する。
ちなみに,Alder Lakeの製造に使用されるプロセス技術は「Intel 7」である。Intel 7とは,かつてIntelが「10nm Enhanced SuperFin」と呼んでいたプロセス技術のことで,Tiger Lakeなどが用いる「10nm SuperFin」の改良版だ(関連記事)。消費電力あたりの性能は,10%ほど向上しているという。
話を戻そう。Alder Lakeの足回りで注目に値するのは,DDR5 SDRAMとPCI Express(以下,PCIe) 5.0への対応だろう。
まずDDR5 SDRAMは,現行のDDR4 SDRAMのおよそ1.5倍のメモリ帯域幅を持つメモリで,Alder Lakeでは「DDR5-4800」と,低電圧版の「LPDDR5-5200」に対応する予定だそうだ。DDR5-4800のメモリ帯域幅は38.4GB/sで,LPDDR5-5200では51.2GB/sに達する。メインメモリもかなりの広帯域幅になるという理解でいいだろう。
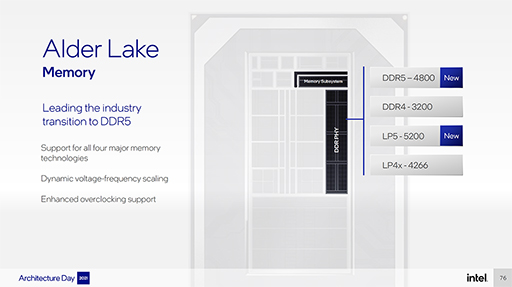 |
また,単体GPUの接続で重要なPCIe 5.0は,現行のPCIe 4.0と比べて2倍のインタフェース帯域幅を持つ。1レーンでは約8GB/s(双方向,片方向では約4GB/s),GPU向けの16レーンだと128GB/s(同64GB/s)というスペックを有する。もちろん,GPU側がPCIe 5.0に対応する必要もあるが,多少はグラフィックス性能向上に寄与するかもしれない。
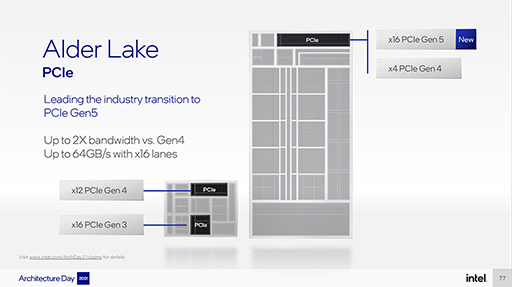 |
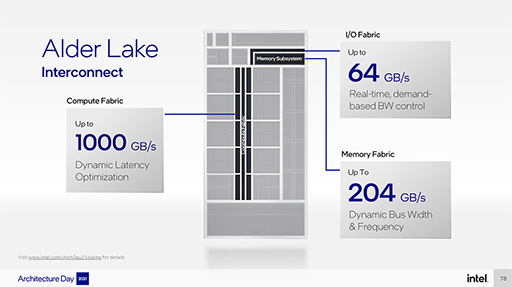
合計16基のCPUコアと広帯域幅のメモリやI/Oインタフェースを備えるとなれば,当然ながら,それらを接続する内部ファブリックにも相応の性能が求められる。そこでAlder Lakeでは,CPU群同士を,最大1000GB/sの帯域幅を持つ内部ファブリックで,CPU群とメモリファブリックとは最大204GB/s,I/Oファブリックとは64GB/sで接続しているそうだ。
また,I/Oファブリックやメモリファブリックは,動的に帯域幅および動作周波数の変更が可能で,これにより電力効率も高めているという。
 |
Alder Lakeは今秋に登場
ゲームPCに大きな変化をもたらすか
Intelによると,Alder Lakeは2021年秋に発売する予定であるとのことだ。
処理能力の異なるCPUコアを組み合わせる構成は,スマートフォンやタブレット端末では,おなじみであるものの,x86系のCPUでは初めてだ。PC向けCPUの進化において,数十年に1度という大きな変化をAlder Lakeがもたらすのではないか,と筆者は予想している。高い電力効率と大幅な性能向上を得られる可能性があるだけに,非常にエキサイティングな新CPUといっていいだろう。製品の登場が待ち遠しい。
 |
IntelのArchitecture Day 2021特設Webページ
- 関連タイトル:
 第12世代Core(Alder Lake)
第12世代Core(Alder Lake)
- この記事のURL:
今すぐできる G123のゲーム
提供:G123
4Gamer.net最新情報
プラットフォーム別新着記事




総合新着記事




企画記事




新着連載
新着レビュー