














ニュース
Intelが予定する2025年のプロセスロードマップをひもとく。2024年の「Intel 20A」で2つの新技術を投入して追撃
 |
もともとIntelは,毎年,自社プロセスに関する動向を説明していた。2020年の場合,8月に「Intel Architecture Day」を開催して,10nmプロセスに関する説明を行い,2019年には「Manufacturing Day」というイベントを10月に実施した。ただ,これらイベントの目的は,その年ごとの状況を勘案して微妙に異なっている。
たとえば2019年の場合は,14nmプロセスの生産能力飽和や10nmプロセスの遅れなどが騒がれていた時期であり,これに向けて生産能力を拡充していることをアピールするのが主目的だった。一方,2020年の場合は,その直前に行われた第2四半期の決算発表の中で7nmプロセスの1年遅延を発表しており,それもあって10nmプロセスの素晴らしさを強調することで,少しでも7nm遅延のインパクトを和らげよう,という意図があった。
 |
自社の生産能力を拡大するとともに
外部の企業も利用するIDM 2.0戦略
まず「そもそもIDM 2.0とは何ぞや」という話であるが,Intelは,デジタル半導体メーカーとしては唯一といってよいIDM(Integrated Device Manufacturer)メーカーになっている。日本語では「垂直統合型デバイスメーカー」といった呼び名になるのだが,ようするに自社の製造設備を使って自社の半導体を製造,販売するメーカーの意味である。
AMDやNVIDIA,Qualcommなどのメーカーは,生産をTSMCやSamsung Semiconductor(以下,Samsung)などに委託するFabless(ファブレス)企業であり,日本で言えばルネサスエレクトロニクスの場合,40nmプロセスあたりまでのMCU(Micro
これに対して,Intelはこれまで,チップセットやEthernetコントローラなどではTSMCを使いつつも,先端プロセスを使う自社CPUは,頑なに自社プロセスでの製造を貫いてきた。ただそれが故に,自社の先端プロセスが不調になると,それがそのまま自社製品に大きな影響を,つまり「消費電力が減らない」とか「動作周波数が上がらない」とか,そもそも「出荷数が足りない」などを及ぼすことになったわけだ。
こうした事態への反省(?)も踏まえて,Gelsinger氏が提唱するIDM 2.0は,
- 自社の生産能力をさらに拡充する
- 外部(主にTSMC)のファウンダリサービスも,これまで以上に活用する
- 自社の生産能力の一部を外部に公開して,ファウンダリビジネスを行う
の3本柱からなる。ようするに,今の自社生産体制は維持するというか,さらに投資を増やす(1.)が,短期的にはTSMCなどに後れを取っているので,追いつくまでの間は他社のファウンダリサービスを積極的に使う(2.)。そしてTSMCなどに追いつくころには,投資効果もあって自社ファブの生産量が過剰になっている公算が高いので,そうした過剰分は外部製品の量産に充てる(3.),というわけだ。なんというか,従来のIntelが取っていた戦略を,拡大再生産した感じである。
 |
さて,Intelのこの戦略は,米国に半導体生産を復帰させたいという米国政府の意向ともマッチした話であり(※欧州も同様な意向を持っている),おおむね好意を持って受け取られている。ただし,IDM 2.0が成功するためには,そもそもIntelのプロセスロードマップを立て直し,きちんと予定どおりにプロセスが利用可能になるとともに,TSMCなどと比較しても見劣りしない,魅力的な将来プロセスを提供する必要がある。今回の発表は,こうしたロードマップを示すために行われたと考えれば分かりやすい。
プロセス名称変更で実態との乖離を解消
というわけで,イベントの背景説明が終わったところで,イベントの内容について説明していこう。
まず最初に発表されたのは,「プロセス名称の変更」である。Intelは今回,製造プロセスの名称を大幅に変更した(表1)。
| 旧称 | 新称 |
|---|---|
| 10nm SuperFin | 10nm SuperFin |
| 10nm Enhanced SuperFin | Intel 7 |
| 7nm | Intel 4 |
| 7nm++ | Intel 3 |
| 5nm | Intel 20A |
| 5nm++ | Intel 18A |
 |
名称変更における最大の目的は,分かりやすさである。もともとIntelのプロセスは,同じプロセスノードの数字を持つ他社のプロセスよりも少し内容が進んでいた。TSMCと比較した場合で言えば,以下のようになっていた(表2)。
| Intel | TSMC |
|---|---|
| 32nm | 28nm |
| 22nm FinFET | 16nm(16FF)相当 |
| 14nm | 16nm(16FF+) |
| 10nm | 7nm相当 |
これは,Intelが先行してプロセスの量産を可能にしていた間は,それほど問題なかった。「Intelは,競合よりも優れたプロセスを先んじて投入できている」と言えたからだ。ところが14nm世代以降,Intelは製品投入がTSMCより遅れた。こうなると,たとえば10nmについても「TSMCより遅れて,しかもTSMCより古いプロセスを投入した」と誤解されやすい。遅れているのは事実だが,中身は同等レベルである。この誤解は,そもそもすでに実態とかけ離れたプロセスノードという数字を使っているのが原因である。
プロセスノード本来の定義は,トランジスタのゲート長である。しかし,これが実際のプロセスと一致していたのは350nm世代あたりまでで,その先は,主にマーケティング的な要因で数字が決まっている。
より正確に言えば,2015年までは「ITRS」(International Technology Roadmap for Semiconductors,半導体技術ロードマップ専門委員会)という組織が2年に1回,向こう10年の半導体技術ロードマップを示しており,ここでプロセスノードとして数字が出てきて,ファウンダリがこれに従っていた。ただ,ITRSは2015年を最後に活動を終了しており,それもあって最近のプロセスノードはファウンダリ各社が勝手に言ってる数字となっている。
そうした事情もあって,Intelも,もう少し誤解を生じさせない数字にするとともに,ノードから「nm」表記を外して,「(数字は)具体的な寸法と無関係である」と強弁できるように配慮した,というあたりか。それがIntel 7/4/3である。
その先に来るIntel 20Aとは何かであるが,もともとITRSのロードマップでも5/4nmの後は3/2.5nm,その次が2/1.5nmというように,小数第1位まで刻んでいた。そうであれば,一桁増やしてオングストローム(Å,1Å=0.1nm)にすることで,この先さらにノードを刻みやすくできる。実際,Intel 18Aも,以前の表記だと「Intel 1.8」とかになってしまい,ちょっと分かりにくいという理由もあるだろう。
Intelの将来プロセスとその特徴
さて,名称は変わったとはいえ,中身は変わらない。10nm SuperFinに関しては,すでにオレゴン州とアリゾナ州,およびイスラエルのファブで「Tiger Lake」(第11世代Coreプロセッサ)や「Xe」アーキテクチャGPUの量産に利用されており,「その次は?」という話になる。
ということで,次に来るIntel 7であるが,これは2021年後半に量産を開始するとしている。これを利用する製品は,クライアントPC向けCPUの「Alder Lake」(アルダーレイク,開発コードネーム 以下同)が2021年中,サーバー向け(つまり次世代Xeon-SP)の「Sapphire Rapids」(サファイアラピッズ)が2021年第1四半期と説明された。
 |
その次に来るのがIntel 4である。こちらは「EUV」(Extreme Ultra Violet,極端紫外線)露光を利用する最初の製品で,かつては7nmと呼ばれていたものだ。TSMCは「N7+/N6」(7nm改良版/6nm)世代,Samsungは「7LPP」(7nm高性能向け)世代でEUVを採用しており,すでに量産に入っているが,Intel 4の導入は2023年前半となる。
 |
このIntel 4は,クライアントPC向けCPUの「Meteor Lake」(メテオレイク)と,サーバー向けCPUの「Granite Rapids」(グラナイトラピッズ)で利用される予定である。Meteor LakeはクライアントPC向けとしてはIntel初のチップレットアーキテクチャ――Intel用語では「Compute Tile」――を採用した製品ということになる(※1)。IntelによるとMeteor Lakeは,2021年第2四半期にTaped in(物理設計を開始)したとされる。それはつまり,プロセッサの物理設計に必要となるPDK(Process Development Kit)が用意できたという意味でもある。
PDK 通常はファウンダリが半導体ベンダーに提供するもので,そのプロセスを利用してLSIを製造するために必要な基礎データと,ライブラリ,シミュレーションツールなどをまとめたもの。これがないとそもそも設計が始められない。
このIntel 4から半年遅れて2023年後半には,Intel 3を投入する。従来の表記だと「7nm++」に相当するので,Intel 4のマイナーバージョンアップといった感じだ。過去の事例で言えば,Intelの「14nm+」が「14nm++」になったような感じだろうか。
 |
さて,ここまでは,基本的に従来もアナウンスしていた話であり,TSMCなどと比較して遅れが目立つ。Intel 4に相当するのは,TSMCの「N5」や「N5P」,Intel 3はTSMCの「N4/N3」に相当する。TSMCは,すでにN5を量産開始しており,N5Pは2021年後半に量産開始予定なので,これは1年半遅れだ。N4は2022年前半,N3は2022年後半に量産開始の予定なので,こちらも1年遅れという計算になる。
※1 初代のノートPC向けCoreプロセッサ「Arrandale」(開発コードネーム)をチップレットアーキテクチャと強弁することも不可能ではないが,どちらかと言えば不出来な製品だったこともあって,あえて取り上げたりはしていない。また2020年に登場したノートPC向けプロセッサ「Lakefield」も,ある意味ではチップレットなのだが,こちらは3D積層技術の「Foveros」を前面に押し出していることもあって,やはりチップレット扱いはされていない。
2つの新技術を投入するIntel 20A
こうした遅れを一気にキャッチアップするのが,Intel 20Aである。特徴は「RibbonFET」と「PowerVia」だ。
 |
まずRibbonFETとは,FinFETの次に来るトランジスタ「GAA」(Gate All Around)として,長らく研究開発が進められてきたものだ。もともとFinFETの構造というのは,次に示すスライドのSuperFinを,右下から左上に向けて見たような構造(図1)になっている。
 |
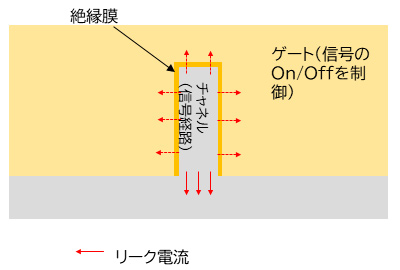 |
「チャネル」というのが信号が流れる経路で,これを薄い「絶縁膜」でカバーすることで,チャネルが「ゲート」という壁を貫通している格好である。この場合,絶縁膜でカバーされている部分からは,リーク電流は流れない(流さないための絶縁膜だ)のだが,ウェハのベース部分と接しているところからはリーク電流が発生する。だからなるべくFinを細く,かつ高くすることで,リーク電流を抑えようというわけだ。しかし,今度はFinの強度が取れずに倒れたり,折れたりといった問題が出やすい。
そこで配線経路をベース部分と完全に分離したのがGAA(図2)である。
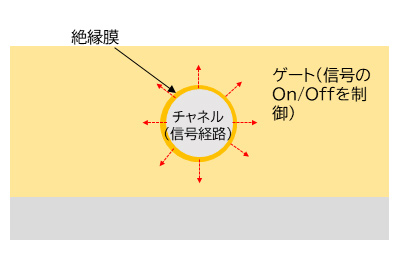 |
こうなると,配線経路のどこからもリーク電流が発生しにくくなる。昨今のトランジスタにおける消費電力の大部分がリーク電流に起因することを考えると,GAAで大幅に消費電力が下がることを期待できるというわけだ。
ちなみに,配線材料としてはナノワイヤとかナノシートを利用する方向で,Samsungはカーボンナノシートを利用した「MBCFET」(Multi Bridge Channel FET)を自社のGAAプロセスに採用予定である。Intelもナノシートを利用して,きしめん状のチャネルを構成することにしたようだ。
 |
GAAに加えてもうひとつ,Intel独自の技術にPowerViaがある。ようするに電力を基板の裏側から供給する,というものだ。
 |
もともと半導体ウェハ上では,トランジスタは,
| 上 | 電源層 |
|---|---|
| ↑ | Global Interconnect |
| Local Interconnect | |
| ↓ | トランジスタ層 |
| 下 | シリコン |
という形で積層されている。まずシリコン上にトランジスタを構築して,その上に「Local Interconnect」(個々のトランジスタの配線や隣接するトランジスタの配線など)を積層し,ついで「Global Interconnect」(回路ブロック同士の接続など)を,その上に電源層を積層する構造だ。
電源層は,文字どおり電源をLSIの全体に分配するための配線だから欠かせないのは間違いないが,最近は,あるブロックへの電源供給を断つことで省電力化を図る「Power Gating」技術なども多用されているので,配線は非常に複雑化している。その一方で,Local Interconnectもどんどん複雑化しており,配線長が長くなりがちである。この配線長が長くなると,そのまま消費電力が増える(配線抵抗が馬鹿にならない)うえ,動作周波数を制限する※2ことになるため,配線はなるべく短縮化したい。
※2 配線が長くなると,これに起因してRC回路というものが生成されてしまい,RC回路の時定数が動作周波数の上限を決めてしまう。
こうした問題を解決する手段のひとつとして,電源層をまるごと基板の裏に構成してしまうというものがPowerViaだ。つまり以下のように積層する。
| 上 | Global Interconnect |
|---|---|
| ↑ | Local Interconnect |
| トランジスタ層 | |
| ↓ | シリコン |
| 下 | 電源層 |
なぜこれが良いのかと言えば,これまでLocal InterconnectやGlobal Interconnectは,電源層の配線を回避しながら配線する必要があり,これが配線距離を余計に伸ばすことにつながっていた。これがなくなるだけでも,配線がだいぶ楽になるのは間違いない。
もちろん弊害もある。今度はトランジスタに電源を供給するために,シリコンを貫通させる形(Via:ビア)で電極を用意する必要があるからで,これはコスト増につながるだろう。その弊害を考慮しても,PowerViaには有用性があるとIntelは判断したようだ。
さて,このIntel 20Aは,2024年前半に投入予定という。おそらく,このあたりでIntelのプロセスは,TSMCに並ぶと思われる。当初TSMCは,GAAに消極的で,2024〜2025年のタイミングで投入としていた。しかし,2021年7月末にTSMCの取締役会は,GAAを使う「N2」のファブを2022年から建設開始,2023年に設備を導入して2024年に量産を開始するという計画を承認したことが報じられた。
また,Samsungは当初,2020年にGAAを利用した「4GAE」(GAA Early)を量産開始予定だったが,その後,GAAは2021年に3nm世代から導入(3GAE)に変更。さらに,これが2022年に伸びたが,最新のロードマップでは3GAEは見送り(社内評価のみで顧客には提供しない)となり,2023年に後継の3GAP(GAA Performance)を導入するとしている。なんとなく,もう1年くらい伸びる気がするが,2023〜2024年には量産開始されるだろう。つまり何も問題がなければ,2024年あたりにTSMCとSamsung,Intelがほぼ同じレベルに並ぶことになる。
 |
3D積層技術の新世代
Foveros OmniとFoveros Direct
 |
Intelはすでに,「EMIB」(Embedded Multi-die Interconnect Bridge)と呼ばれる技術を広く利用している。これは,Silicon Interposer(配線層)をベースとして高密度配線を可能にするというもので,TSMCなどが提供する「CoWoS」(Chip
バンプというのはLSIの裏にある半田付け用のボール型突起のことで,これまでは直径55μmのボールに対応していたのが,45〜40μmに縮小したものも提供するという話である。
また,Lakefieldで登場した3D積層技術である「Foveros」も,第2世代が開発中で,これはMeteor Lakeのほか,サーバー向けGPUである「Ponte Vecchio」(ポンテベッキオ)に採用されるとしている。
 |
 |
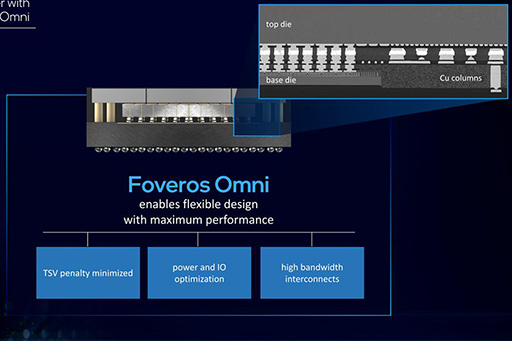
さらに,新しいコンポーネントとして「Foveros Omni」と「Foveros Direct」の発表もあった。
 |
Foveros Omniは,かつて「ODI」(Omni-Directional Interconnect) Technologyと呼ばれていた技術で,TSMCの技術「InFO」(Integrated Fan-Out)に近いものだ(Foverosそのものが,かなりInFOに近い)。InFOや従来のFoverosでは,チップの外側にViaがそびえ立っていたため,配線が結構長かった。それがFoveros Omniでは,Base DieとTop Dieを向かい合わせにして,間に挟まるInterposerでの配線を最小にするものと思われる。
 |
Foveros Directはその先を行くもので,Interposerを挟まずにBase DieとTop Dieを直接接続できる技術である。Intelによれば,このFoveros OmniおよびDirectは,どちらも2023年から提供される予定だ。
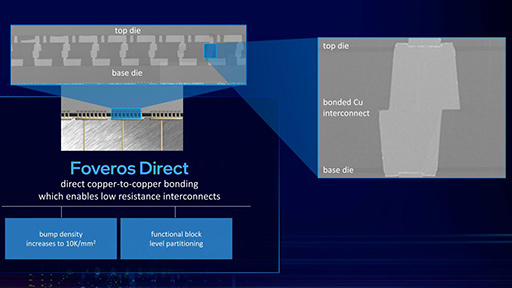 |
こうした技術ロードマップにより,2025年にIntelは,ファウンダリビジネスでも技術的にトップの座に返り咲きたい,というのがGelsinger氏の野望である。ただ,現実問題として,2024年のIntel 20A投入までの間は,TSMCにビハインドを負っているのは間違いない。この間は積極的にTSMCを使うなどして,カバーしたいというわけだ。
これがうまくいくかどうかは,そもそも2020年に1年遅れをアナウンスせざるをえなかった旧7nm(=Intel 4)を,2023年に立ち上げられるかどうか次第である。過去のIntelは,新プロセス導入時にYield(歩留まり)の改善具合をグラフで示すなど,口だけでなく証拠を示してきていた。しかし,10nmや7nmに関してはこうした話が一切なく,「問題は解決した」というだけなのをはたして信じられるかどうか。
あるいはIntel 20Aについても,競合であるTSMCは手を抜いていない。韓国特許庁が7月20日に発表したGAAに関する特許のまとめ(関連リンク)によると,2011年以降に取得されたGAA関連特許の累計取得数は,TSMCがトップで全体の31.4%,2位がSamsungで20.6%であり,Intelは5位の4.5%でしかない。ここからどこまで巻き返しできるか。
とりあえずは,2021年中に投入予定のIntel 7が,どこまでまっとうなプロセスかを見て判断したいところだ。
Intelの当該プレスリリース
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー