 |
| GeForce 7800 GTXのリファレンスカード |
「こちら」の記事で説明したように,GeForce 7800 GTX(以下7800 GTX)は開発コードネーム「NV47」として開発が進められてきたが,プロジェクト後半に「G70」と改められた経緯がある。要するに,7800 GTXはNV4x(=GeForce 6シリーズ)の改良版というわけだ。
では,7800 GTXは,GeForce 6シリーズと比べて何が変わったのだろうか。今回は,GeForce 6シリーズ最上位となるGeForce 6800 Ultra(以下6800 Ultra)と,前後編に分けて細かく比較していきたいと思う。
7800 GTXのコアアーキテクチャを示すブロック図は以下のとおりだ。右は6800 Ultraのものである。
 |
 |
| 7800 GTXのブロック図(左)と6800 Ultraのブロック図(右) |
まずは全体を大づかみしておこう。最上段のブロック「HOST/FW/VTF」は,システム側からの入力を意味している。HOSTはCPUからの入力,FWは「FirstWrite」の略で,グラフィックスチップがメインメモリから直接データを読み込める仕組みのこと。VTFは「Vertex Texture Fetching」の略だ。Vertex Texture Fetchingはテクスチャに格納しておいたベクトルデータを取り出せる仕組みのことで,このデータと,現在入力中の頂点データを組み合わせた頂点処理を行えるが,これについては後述する。なお,6800 Ultraのブロック図にこのブロックは記載されていないが,同じものが存在している。
いずれの図でも,入力された頂点データストリームは頂点パイプラインによって最初に処理される。図の上方で横に並んでいるブロック(7800 GTXでは8基,6800 Ultraでは6基)が,頂点パイプライン(Vertex Pipeline)を形成する頂点シェーダ(Vertex Shader)ユニット群だ。詳細は後述するが,ここで頂点処理が行われ,「Setup」でポリゴンとピクセルの対応付けも行われて,データはピクセルレンダリングパイプライン(Pixel Rendering Pipeline,以下ピクセルパイプライン)へ渡される。
図の中央にある,やはり横並びのブロック(7800 GTXでは24基,6800 Ultraでは16基)はピクセルパイプラインを形成するピクセルシェーダ(Pixel Shader)ユニット群だ。
このピクセルシェーダユニット群を横に貫くような形で描かれているオレンジのバーはL2テクスチャキャッシュ(L2 Texture Cache,スライドでは「L2 Tex」と表記)。グラフィックスメモリ(7800 GTXの図だと一番下の紫色ブロック。6800 Ultraの図では省略されている)と接続されていることからも分かるように,グラフィックスメモリへのアクセスが生じたとき,L2テクスチャキャッシュ上にデータがあれば,実際にグラフィックスメモリにアクセスしないで済むような設計になっている。
各ピクセルシェーダユニットは,固有のL1テクスチャキャッシュを内包するが,L1,L2という二段構えのキャッシュシステムはCPUのそれとよく似ている。なお,L2テクスチャキャッシュは頂点シェーダと共有する設計だ。ちなみに,CPUと違ってグラフィックスチップのL1/L2テクスチャキャッシュ容量はなぜか常に非公開で,明らかにされたことはない。
ピクセルパイプラインから出てきた演算結果を実際にグラフィックスメモリへ書き込むのが,図下段にある横並びのブロック(7800 GTX,6800 Ultraともに16基)のラスタライズオペレーションユニット(Rasterize Operation Unit,以下ROPユニット)だ。ROPユニットはアンチエイリアス処理なども行っている。
実際にピクセルをグラフィックスメモリに書き込むかどうかは,書き込む直前にROPユニット内で深度(Z値)バッファテストを行ってから決定される。ここも詳細は後述するが,ピクセルの書き込みがあると同時に,対応する深度バッファの内容も更新。深度バッファの内容はピクセルパイプラインの入り口にフィードバックされており,あるピクセルが「描画されない」と断定されたとき,ピクセルパイプライン前に弾く「早期カリング処理」に役立てられている。
まぁ,このブロックは抽象的なもので,「上から下に向かって仕事を発注する」というような捉え方でいいだろう。「こちら」の記事から再掲になるが,7800 GTXの主なスペックは以下の表のとおりだ。
頂点パイプラインは6800 Ultraが6本だったのに対し,7800 GTXでは8本へ増加した。
そして,その各頂点パイプラインの頂点シェーダは以下のような構造になっている。
 |
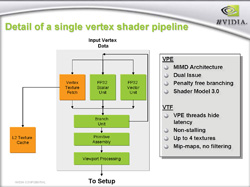 |
| 7800 GTX(左)と6800 Ultra(右)の頂点シェーダブロック図。「FP32 Vector Unit」(FP32-VU)は四要素(αRGB)32ビット浮動小数点ベクトルデータ(w,x,y,z)同士の積和算をシングルサイクルで処理可能だ。「FP32 Scalar Unit」(FP32-SU)はスカラ値(単数)の正弦,余弦,指数,対数演算をこなせるユニットである |
そう,見れば分かるように,7800 GTXと6800 Ultraの頂点シェーダアーキテクチャに変更はないのだ。
頂点シェーダユニットはMIMD(Multiple Instruction/Multiple Data),SIMD(Single Instruction/Multiple Data)両対応アーキテクチャとなっている。MIMDとは複数命令と複数データを同時処理できる仕組み,SIMDは1つの命令で複数データを処理できる仕組みのこと。つまり「FP32 Vector Unit」と「FP32 Scalar Unit」は1サイクル期間の間に同時実行可能で,これがいずれのスライドにもある「Dual-Issue」(2命令同時発行)の記述につながっている。
スライドにある「Vertex Texture Fetch」は頂点シェーダからテクスチャを取り扱う仕組みのことで,実際にオレンジ色で描かれているユニットがVertex Texture Fetching(以下VTF)を行っている。VTF用ユニットはL2テクスチャキャッシュと直結しており,テクセル(テクスチャを構成するピクセル)は,基本的にL2テクスチャキャッシュから読み出される。L2テクスチャキャッシュ上にないテクセルは,グラフィックスメモリから読み出す必要があるのは前述したとおりだ。
ここでVTFについて簡単に解説しておこう。「テクスチャと言えば画像」というイメージがあるが,GeForce3以降,つまりプログラマブルシェーダ時代になってからは「テクスチャには多様なデータを入れておき,後でプログラマブルシェーダを使って好きにこねこねする」という使い方が一般化した。テクスチャに微細凹凸面の向きを表す法線ベクトルを格納し,これにピクセル単位の光源処理を行うことで見かけ上の凹凸を表現する,法線マップを利用したバンプマッピング,俗称「法線マッピング」はこの一例である。
そうしたなかで「頂点シェーダにも多目的用途なメモリ空間としてテクスチャを扱えるようにしよう」と実装されたのがプログラマブルシェーダ3.0(シェーダモデル3.0,以下SM3.0)のVTFという考え方だ。VTFはとくに「頂点テクスチャリング」と呼んだりする場合もある。VTFの活用において最も分かりやすいのは,3Dモデルを頂点テクスチャの内容に従って変形させる「ディスプレースメントマッピング」だろう。
 |
 |
| 変位データ(ディスプレースメントデータ)をテクスチャ化して,これを基に3Dモデルの頂点を変位させて形状の変更を行うディスプレースメントマッピング技術。この話のたびにMatroxのスライドを使っているのは,見た目にいいスライドがほかにないから……。許されたし |
このVTFは,現在の頂点シェーダ3.0仕様では以下のような制限があり,これは7800 GTXでも改善されていない。
- アクセスできるテクスチャがシングルパスでは4枚まで
- テクスチャにMIP-MAP※が利用できるが,MIP-MAPレベルを明示指定しておかなければならない
- テクスチャフィルタリングが適用できない
※ミップマップ。あらかじめ縦横の辺を2分の1ずつに縮小させた(面積比でいうと4分の1,16分の1,64分の1)テクスチャをあらかじめ用意しておき,この縮小テクスチャからテクセル読み出しをする仕組みのこと。詳細は「こちら」の記事を参照してほしい。
また,いまだにVTFを効果的に利用するための開発ツールが整備されていなかったり,ATI TechnologiesのRadeonシリーズがプログラマブルシェーダ2.0仕様でVTFをサポートしていない(つまり,VTFを想定してゲームを開発すると,Radeonシリーズで正常に動作しない)という問題があったりする。結果として,3Dゲーム開発者に積極的なVTF活用を思いとどまらせてしまっているというのが現状だ。
なお,VTFでテクスチャキャッシュのミスが発生した場合,グラフィックスメモリからテクスチャを読み出す必要があるのはすでに述べたとおりだが,この作業はグラフィックスチップのクロックサイクルからするととてつもなく長い時間がかかる。そこで7800 GTXでは――6800 Ultraでも同様だが――実テクスチャアクセスが発生するとスレッド切り替えを行い,ほかの頂点データの処理に取りかかる仕組みを導入している。これがスライドにある「VPE Threads hide latency」である。
1基の頂点シェーダユニットは,実際には複数の頂点データ処理を担当できる仕組みを備えている。要するに,グラフィックスチップ内部では入力データを1スレッド扱いにしたマルチスレッディングが行われているのだ。
革新的な改良は一切ないが,3Dグラフィックスパイプラインの基本事項確認の意味合いも兼ねて,頂点シェーダからピクセルシェーダへの流れも簡単に解説しておこう。
グラフィックスチップは,頂点シェーダから出力された頂点データが描画基準となる視界からはみ出ているかどうかを判断し,はみ出ていればその頂点データの処理を打ち切る。これを「Cull」という。さらに,視界から切り取られていれば「Clip」処理を行い,"その先"へ進める頂点データからなるポリゴンだけを,画面上の画素(ピクセル)という単位に分解して対応づける(「Setup」)。この部分の概念は決まり切った仕事なので,以前のグラフィックスチップから大きな進化はない。
分解されたピクセルは,本当に描かれる可能性があるのかを深度情報と比較して判断(「Z-Cull」,前述した「早期カリング処理」のこと)され,可能性があれば,ピクセルパイプラインへ処理が移される。
……というわけで,前編ではブロック図の全体を上から順に追いつつ,頂点シェーダユニット,VTFについてまとめ,ピクセルシェーダユニットにデータが渡される直前までを説明してきた。後編では,6800 Ultraに対して数が1.5倍に増えたピクセルシェーダユニットを中心に,気になる製品ラインナップなどについても考察していきたいと思う。(トライゼット 西川善司)










